
Autonome KI-Agenten sollen Datenpipelines bauen, Qualität in Echtzeit prüfen und Governance automatisch durchsetzen. Klingt nach Zukunft. Warum scheitern dann so viele Organisationen schon an einem aktuellen Datenkatalog?
Die neue Verheißung
Metadaten, Datenkataloge, semantische Schichten, Echtzeit-Governance: Vier Begriffe, die in jeder aktuellen Analyse zu KI im Datenmanagement auftauchen. Die Botschaft ist klar. Autonome Agenten übernehmen die Drecksarbeit. Sie erkennen Anomalien, reparieren Pipelines, klassifizieren Daten und steuern Zugriffsrechte. Alles automatisch, alles in Echtzeit, alles kontextbewusst.
Die Prognosen lesen sich beeindruckend: Bis 2029 sollen 75 Prozent aller Data-Engineering-Workflows durch Agenten automatisiert sein. Bis 2028 werden angeblich ein Drittel aller Interaktionen mit generativer KI autonome Agenten auslösen. Die großen Plattformanbieter überbieten sich mit neuen Agent-Funktionen. Datenbanken werden zu "Knowledge Sources", ETL-Workflows zu "selbstheilenden Pipelines", und Governance-Regeln sollen sich dynamisch an den Kontext anpassen.
Die Architektur dahinter ist durchaus durchdacht. Drei Typen von Agenten sollen zusammenarbeiten: spezialisierte Task-Agenten für einzelne Aufgaben wie Bereinigung oder Transformation, Orchestrierungsagenten, die Workflows über Systemgrenzen hinweg koordinieren, und Multi-Agenten-Systeme, die all das zu einem selbstlernenden Ganzen verbinden. In der Theorie entsteht so ein Datenmanagement, das sich selbst optimiert und menschliches Eingreifen nur noch in Ausnahmefällen braucht.
Für IT-Führungskräfte klingt das nach einer strategischen Entscheidung, die keinen Aufschub duldet. Wer jetzt nicht investiert, fällt zurück. Die Frage, die in den Präsentationen fehlt: Was passiert, wenn du investierst, aber deine Organisation die Voraussetzungen nicht erfüllt?
Was die Praxis zeigt
Ich habe in den vergangenen Jahren eines gelernt: Zwischen dem, was Analysten als nächsten Schritt empfehlen, und dem, was Organisationen tatsächlich umsetzen können, liegen oft Jahre. Manchmal Jahrzehnte. Das ist keine Klage. Das ist eine Beobachtung, die sich in jedem Technologiezyklus bestätigt hat.
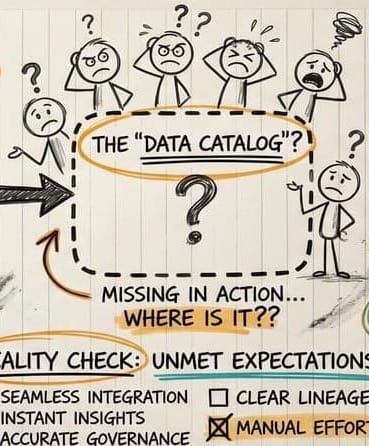
Vor nicht langer Zeit startete eine große Organisation ein Datenqualitäts-Projekt. Das Ziel klang vernünftig: Datenprobleme systematisch identifizieren und beheben. Regelbasiert, automatisiert, nachvollziehbar. Das Projekt kam ins Stocken, bevor es richtig begonnen hatte. Nicht weil die Technik fehlte. Sondern weil niemand wusste, welche Daten überhaupt wo liegen und was sie bedeuten. Kein Datenkatalog. Keine maschinenlesbaren Geschäftsdefinitionen. Keine klaren Verantwortlichkeiten.
Die Qualitätsregeln konnten nicht greifen, weil ihr Bezugspunkt fehlte. Das Projekt musste einen Schritt zurück: erst inventarisieren, dann messen. Die Erkenntnis war schmerzhaft, weil sie banal klingt. Aber genau das macht sie so relevant.
Jetzt stell dir vor, was passiert, wenn du auf dieser Grundlage nicht nur regelbasierte Prüfungen aufsetzt, sondern einen autonomen Agenten. Einen Agenten, der eigenständig Zugriffsrechte anpasst. Der Daten als "nicht sensibel" klassifiziert. Der Pipelines umbaut, weil sein Modell eine Anomalie erkennt, die keine ist. Ein solcher Agent braucht eine semantische Schicht als Fundament: maschinenlesbare Geschäftsdefinitionen, konsistente Ontologien, gepflegte Metadaten. Diese Schicht verwandelt rohe Daten in Kontext. Ohne sie ist ein Agent ein Werkzeug ohne Landkarte.
In den meisten Organisationen, die ich kenne, ist diese semantische Schicht schlicht nicht vorhanden. Nicht in Ansätzen mangelhaft. Nicht vorhanden. Das bedeutet: KI-Agenten würden Prozesse auf Daten automatisieren, deren Bedeutung sie nicht kennen. Sie würden Beziehungen herstellen, die nicht existieren, und Klassifizierungen vornehmen, die auf Annahmen statt auf Wissen beruhen.
Im hochregulierten Behördenumfeld kommt eine weitere Dimension hinzu, die in keiner Produktdemo auftaucht: Verantwortung. Wenn ein Agent autonom Governance-Entscheidungen trifft, etwa zur Klassifizierung oder Zugriffssteuerung, dann ist das keine technische Frage mehr. Wer trägt die Verantwortung, wenn der Agent personenbezogene Daten falsch einstuft? Wer haftet, wenn als Verschlusssache eingestufte Informationen durch eine algorithmische Fehlklassifizierung in den falschen Bereich gelangen? Im Kontext von DSGVO und Geheimschutz ist "autonome Governance" kein Feature. Es ist ein Risiko, solange die menschliche Letztentscheidung nicht architektonisch verankert ist.
Dieses Problem wird durch die Natur der neuen Agenten verschärft. Anders als regelbasierte Systeme arbeiten sie nichtdeterministisch. Gleicher Input kann zu unterschiedlichem Output führen. Das macht sie flexibel und leistungsfähig, aber auch schwerer zu auditieren. In einem Umfeld, in dem Nachvollziehbarkeit keine Option, sondern eine rechtliche Anforderung ist, muss dieser Punkt von Anfang an in der Architektur gelöst werden.
Ich habe mich dabei ertappt, wie ich anfangs selbst fasziniert war von der Idee selbstheilender Datenpipelines. Wer wäre das nicht, nach Jahren mühsamer manueller Pflege? Aber Faszination ist kein Ersatz für eine ehrliche Bestandsaufnahme. Und ehrlich ist: Die meisten Organisationen sind nicht drei Monate, sondern drei Jahre von einem sinnvollen Einsatz autonomer Daten-Agenten entfernt.
Was daraus folgt
Die gute Nachricht: Du musst nicht auf KI-Agenten verzichten. Du musst nur die Reihenfolge einhalten. Und die beginnt nicht mit der Agentenplattform, sondern mit vier Grundlagen, die sich nicht abkürzen lassen.
Datenkatalog vor Automatisierung. Wer seine Daten nicht inventarisiert hat, kann keine sinnvollen Qualitätsregeln definieren. Und ohne Qualitätsregeln hat ein Agent kein Fundament. Das klingt trivial. Trotzdem beginnen die meisten Projekte mit dem Tool statt mit den Daten. Ein pragmatischer erster Schritt: Starte nicht mit dem Anspruch, alle Daten zu katalogisieren. Starte mit den drei bis fünf Datenbereichen, die für deine kritischsten Prozesse relevant sind. Lieber fünf Prozent gut dokumentiert als hundert Prozent in einer Tabelle, die niemand pflegt.
Human-in-the-Loop als Architekturprinzip. Besonders in Bereichen mit hohen Compliance-Anforderungen darf die menschliche Letztentscheidung keine Notlösung sein. Sie gehört in die Systemarchitektur, nicht in eine Fusszeile im Betriebshandbuch. Jede Governance-Entscheidung, die ein Agent trifft, braucht eine definierte Eskalationsstufe. Konkret bedeutet das: Bevor du einen Agenten in Betrieb nimmst, definierst du, bei welchen Entscheidungen er autonom handeln darf, bei welchen er einen Vorschlag macht, und bei welchen er stoppt und einen Menschen einbezieht. Diese Dreistufigkeit ist kein Luxus. Sie ist die Mindestanforderung für regulierte Umgebungen.
Definiere das Outcome, nicht das Tool. Nicht "wir wollen KI im Datenmanagement" ist die richtige Zielsetzung. Sondern "wir wollen Datenqualitätsprobleme in Pipeline X innerhalb von vier Stunden statt vier Tagen erkennen und beheben". Erst wenn das Ziel messbar formuliert ist, lässt sich beurteilen, ob ein Agent die richtige Lösung ist oder ob ein gut konfiguriertes Regelwerk ausreicht.
Und noch etwas, das oft übersehen wird: Souveränität der Metadaten. Wem gehören die Geschäftsdefinitionen und Klassifizierungen, die ein Agent auf einer Cloud-Plattform verarbeitet? Diese Frage klingt abstrakt. Bis der Anbieter seine API ändert oder seinen Dienst einstellt. Dann wünschst du dir, dass du deine semantische Schicht unter eigener Kontrolle hast. Gerade für europäische Organisationen mit besonderen Anforderungen an die Datenhoheit ist das keine theoretische Überlegung. Es ist eine strategische Entscheidung, die du heute triffst, aber deren Konsequenzen erst in drei Jahren sichtbar werden.
Fazit
KI-Agenten im Datenmanagement sind kein Hype. Sie werden kommen, und sie werden vieles besser machen. Aber sie werden nichts besser machen für Organisationen, die ihre Daten nicht kennen.
Drei Stufen lassen sich nicht überspringen. Auch nicht mit dem klügsten Agenten.
Quick Check: Ist deine Organisation bereit für KI-Agenten im Datenmanagement?
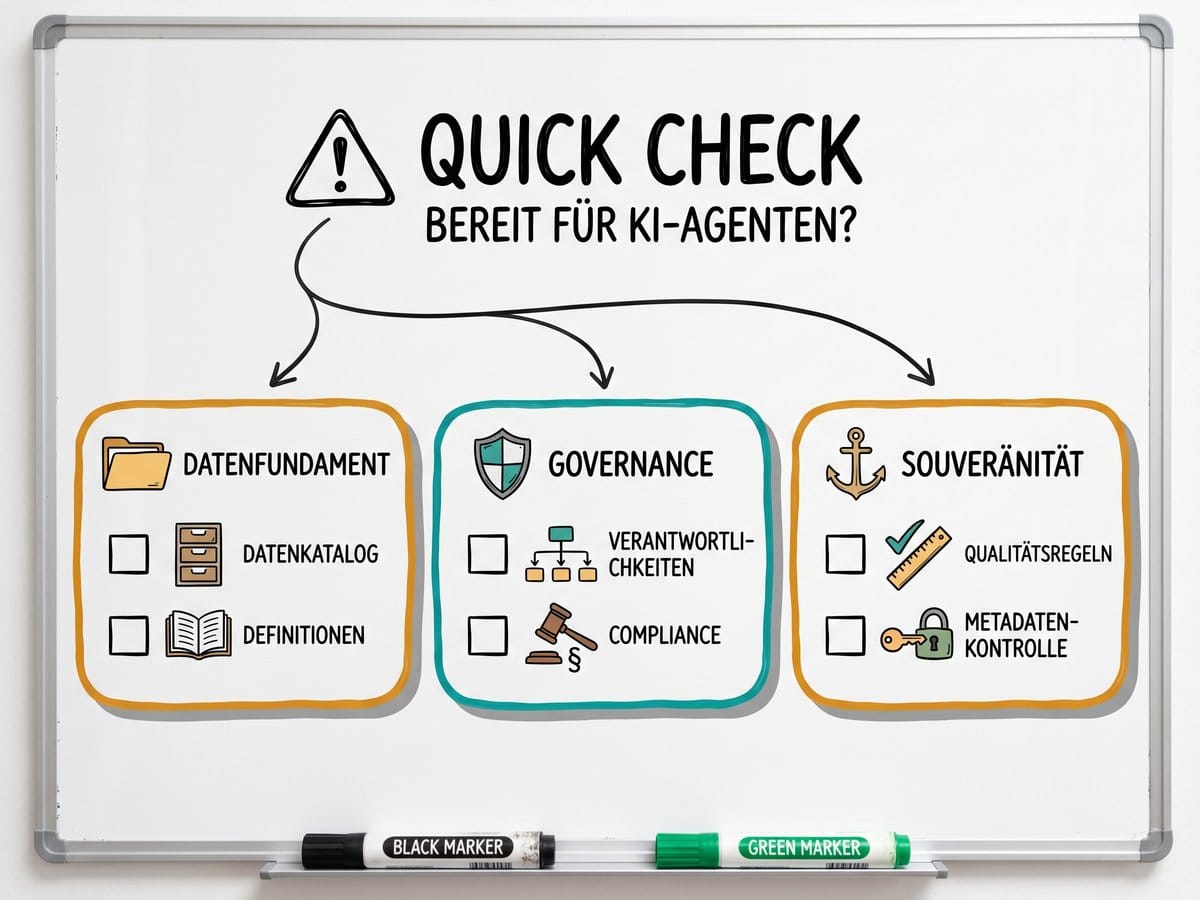
Die folgenden Warnsignale sind keine theoretische Checkliste. Jede rote Flagge deutet darauf hin, dass die Voraussetzungen für agentenbasiertes Datenmanagement noch nicht stehen. Das ist kein Versagen. Es ist die ehrliche Bestandsaufnahme, ohne die kein sinnvoller nächster Schritt möglich ist.
Nimm dir zehn Minuten und geh die Punkte mit deinem Datenteam durch. Wenn mehr als zwei auf deine Organisation zutreffen, ist die Investition in Grundlagen nicht nur sinnvoller als die Investition in Agenten. Sie ist die Voraussetzung dafür, dass die Agenten-Investition später überhaupt Wirkung zeigt.
Diskussionen der Mitglieder